
Altiora Petamus
[cs231n] 14.Visualizing and Understanding 본문
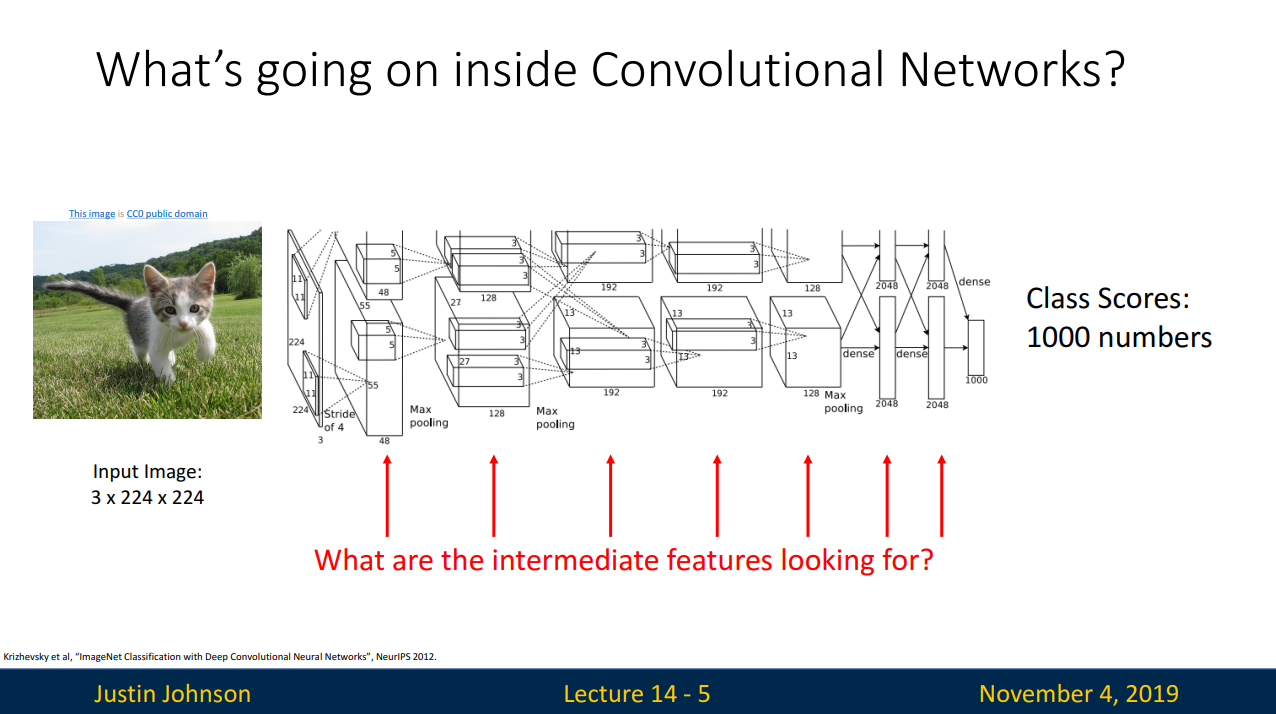
- ConvNets의 내부는 어떻게 생겼을까?
- 입력데이터 -> 변화 -> Class scores 의 과정에서 "변화" 는 어떤 것을 의미할까?

- ConvNet에서 가장 쉽게 알아볼 수 있는 것은 first Layer
- AlexNet의 경우 filter의 크기가 3x11x11의 형태를 취하고 있음
- filter들이 입력이미지를 지나면서 내적하여 만들어진 것이 first Conv Layer
- first layer는 입력이미지와 직접 연산이 되기 때문에 (직접적인 관계가 있기 때문에) 시각화 하는 것만으로도 의미를 알 수 있다.
- 각각의 필터는 입력 이미지에서 다양한 각도와 위치에서의 보색을 기반으로 특징을 찾는다.

- 이전 슬라이드에서 이용한 시각화 기법을 두번째 layer와 세번째 layer에 적용하여 출력한 결과,
출력은 가능하나 해석하는 것이 의미가 없다. - 입력이미지와 직접적인 연관이 없기 때문

- 마지막 레이어는 4096 차원 특징 벡터를 입력으로 최종 class scores를 출력
- 마지막 Hidden Layer를 시각화하는 것으로 알아볼 수 있다. (벡터 저장하는 방식으로 )
- 픽셀공간에서가 아닌 특징 벡터 공간에서 Nearest neighbors를 찾음
- 코끼리의 경우를 보면 픽셀공간이 아니라 특징벡터공간에서 유사한 이미지를 찾은 것을 확인할 수 있다.

- 최종 레이어에서의 차원축소 관점 (4096 -> 2 )
- PCA(Principle Component Analysis) : 고차원 특징벡터를 2차원으로 압축시켜 표현하는 방법
- t-SNE(t-distributed stochastic neighbor embeddings) : PCA보다 많이 쓰이는 특징공간 시각화 기법

- t-SNE를 ImageNet을 분류하려 학습시킨 네트워크의 마지막 레이어에 적용한 모습

- 네트워크 중간에서 뽑은 특징들을 이용하여 이해할 수 있는 것
- 중간 레이어의 가중치가 아닌 activation map을 시각화
- 이를 이용하여 conv layer가 입력에서 어떤 특징을 찾는지 짐작해볼 수 있다.
- 사람의 얼굴 형태에 activation map이 더욱 활성화 된다.
- convNet은 분류문제에 있어서 필요한 특징들을 알아서 학습한다.

- 중간 특징을 시각화 할 수 있는 또 다른 방법
- 어떤 이미지가 들어와야 activation map이 활성화 되는지 알아보는 방법
- conv5의 값은 128 x 13 x 13 의 크기를 갖고 17번째 채널을 참조함
- 많은 이미지들을 네트워크에 통과시킨 다음 각 이미지의 conv5 features를 기록해 놓는다.
- 이 layer는 convolutional layer이기 때문에 반영하는 크기가 부분적이다.
- patch들을 통해 해당 layer가 어떠한 특징을 찾고있는지 알 수 있다.

- Occlusion experiments
- 입력의 어떤 부분이 분류를 결정짓는 근거가 되는지에 관한 실험
- 가렸을 경우 확률이 낮음 (빨강)

- Saliency Maps
- 어떤 픽셀을 보고 '개'라고 판단했을지 알아봄
- 입력이미지의 각 픽셀들에 대해서 예측한 클래스 스코어의 그레디언트를 계산하는 방법


- saliency maps에 지도학습 없이 GrabCut 을 적용하여 segmentation 수행
- 지도학습에 비하여 성능이 낮음
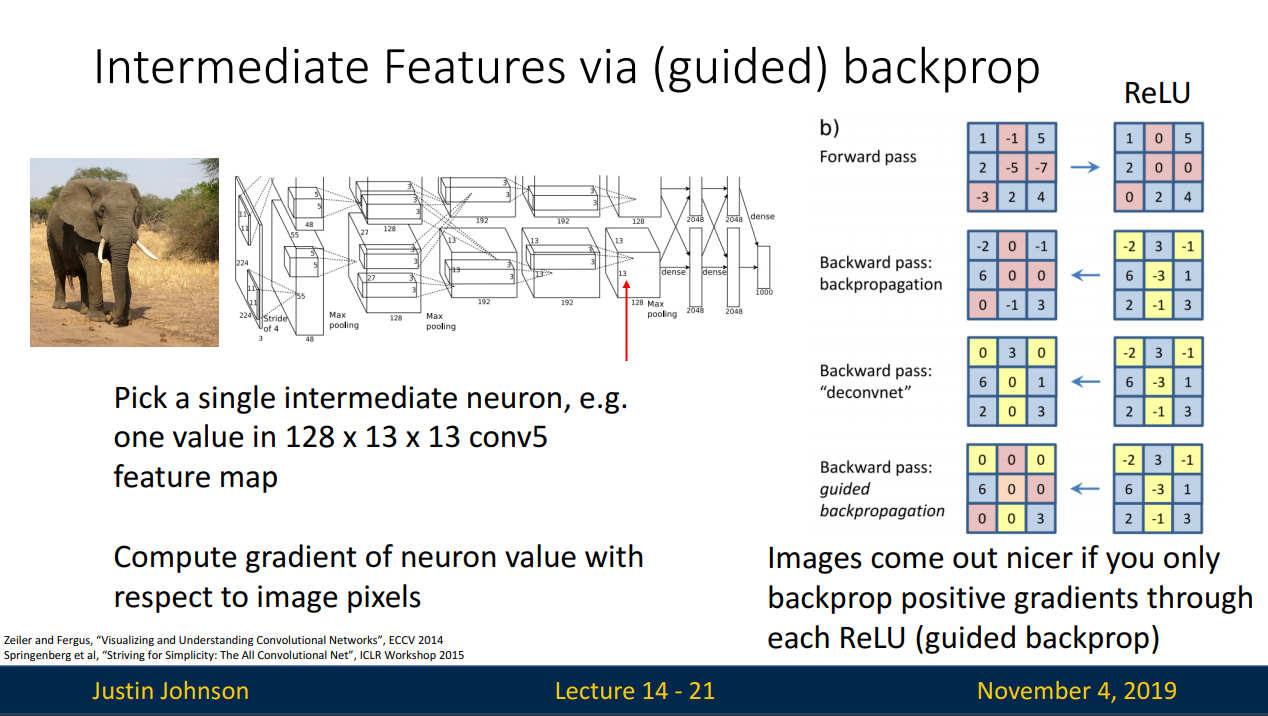
- 클래스 스코어가 아닌 네트워크의 중간 뉴런을 하나 고른후 , 입력 이미지의 어떤 부분이 내가 선택한 중간 뉴런의 값에 영향을 주는지 찾는 방식
- 이미지의 각 픽셀에 대한 클래스 스코어의 그래디언트를 계산하는 것이 아니라, 입력 이미지의 각 픽셀에 대한 네트워크 중간 뉴런의 그레디언트를 계산 (어떤 픽셀이 해당 뉴런에 영향을 주는지 알 수 있다. )
- guided backprop는 일반적인 backprop방식에 약간의 트릭을 가미한 것 (ReLU)

- guided backprop는 saliency maps에 비해 선명하고 좋은 이미지를 출력할 수 있다.
- guided backprop 방법을 통해 maximally activating patches 의 어떤 부분이 가장 영향력이 있는지 알 수 있다.

- guided backprop나 saliency maps등을 계산하는 방법들은 '고정된' 입력 이미지에 대한 연산을 수행한다.
- gradient ascent 방법은 입력 이미지에 의존적이지 않도록 네트워크의 가중치들을 전부 고정시키고 중간 뉴런 혹은 클래스 스코어를 최대화 시키는 이미지의 픽셀들을 만들어 낸다.
- 즉 네트워크의 가중치를 최적화 시키는 방법이 아닌 뉴런이나 클래스 스코어가 최대화 될 수 있도록 입력 이미지의 픽셀값을 바꾸어 주는 방법
- regularizer term 필요 ( 생성된 이미지가 특정 네트워크의 특성에 완전히 과적합 되는 것을 방지)
- 이미지가 특정 뉴런이나 스코어를 최대화 시키는 방향으로 생성되며 자연스러운 이미지를 구현

- 이미지를 초기화 시킨후 네트워크에 통과시키고 특정 뉴런의 스코어를 계산한다.
- 각 픽셀에 대한 해당 뉴런 스코어의 그레디언트를 계산하여 back prop를 수행
- 이미지 픽셀 자체를 업데이트 (스코어를 최대화 하는 방향으로 )

- regularizer 로 L2 norm을 추가한다.

- 최적화 과정에 이미지에 주기적으로 Gaussian blur를 적용
- 주기적으로 값이 작은 픽셀들은 모두 0으로 만듦
- 주기적으로 값이 작은 gradients를 모두 0으로 만듦
- 이는 생성된 이미지를 더 좋은 특성을 가진 이미지 집합으로 주기적으로 매핑시키는 방법이다.

- gradient ascent 를 클래스 스코어가 아닌 중간뉴런의 값을 크게 만들도록 한다면 위와 같이 이미지가 생성됨을 확인할 수 있다.

- adversarial examples
- 임의의 이미지를 다른 임의의 카테고리로 분류하도록 이미지를 조금씩 업데이트 한다.
- 임의의 카테고리라고 분류할 때 까지 이미지를 업데이트 한다.

- 실제로 adversarial examples 를 적용한 결과 위 예제 이미지 처럼 변화가 없는것 같아 보인다.
'SSAC X AIffel > Deep ML - CS231n' 카테고리의 다른 글
| #0.공부를 시작하기 전에.. (0) | 2021.01.04 |
|---|
Comments