
Altiora Petamus
[EXPLORATION] 2-1. scikit-learn Model / Confusion Matrix 본문
[EXPLORATION] 2-1. scikit-learn Model / Confusion Matrix
현석종 2021. 2. 19. 16:15이전 포스트 ( 2. [EXPLORATION] 2. scikit-learn 내장 분류 모델 학습 ) 에서 scikit learn의 데이터셋과 모델을 이용한 간단한 분류 모델을 학습시켜보았다. 이번 포스트에서는 scikit learn의 모델들과 오차행렬에 대하여 기록하고자 한다.
1. Model
1-1) Decission Tree
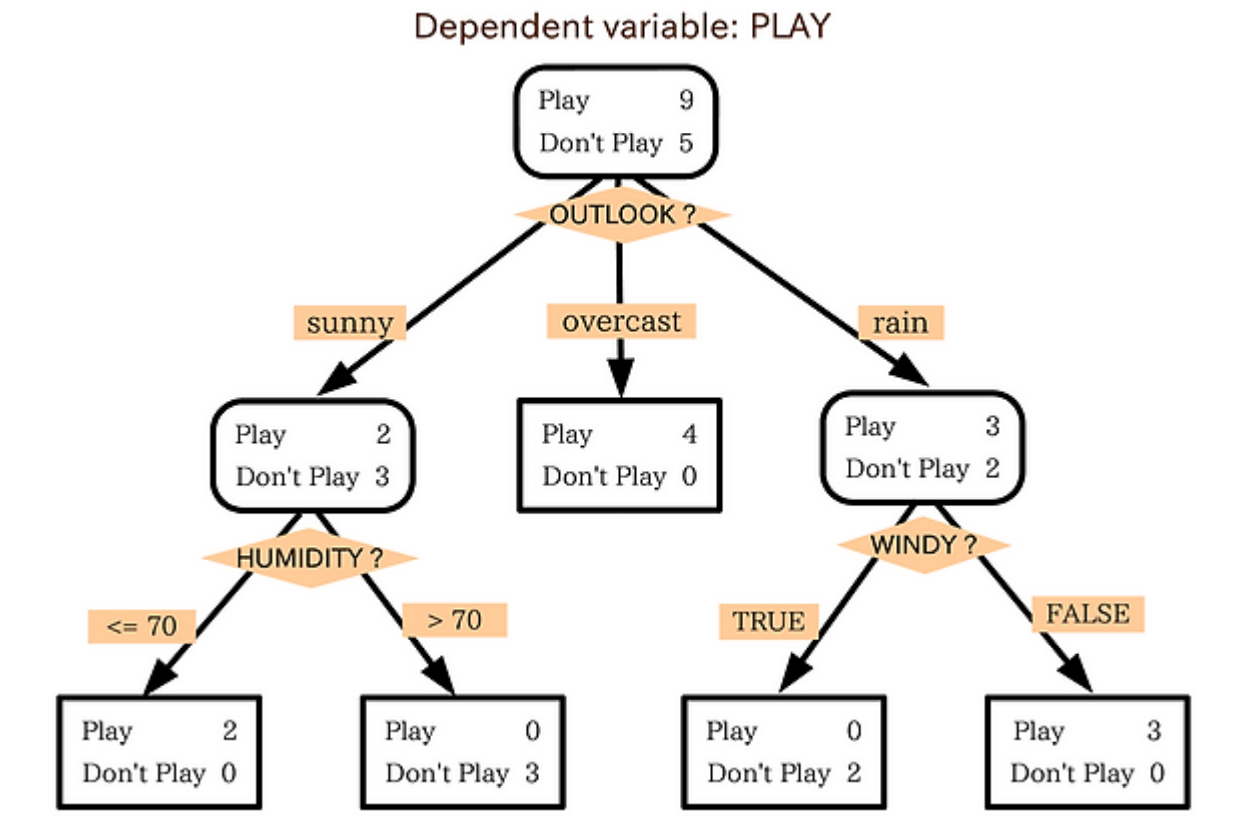
- 데이터의 패턴을 분석하여 예측 가능한 패턴들의 조합으로 나타내며 그 형상이 나무와 같아 붙여진 이름
- 데이터를 이용한 '스무고개'
- 분류 / 회귀 모두 예측 가능
- 분류의 경우 데이터와 해당 label을 참고하여 terminal node에 가장 빈도가 높은 범주에 데이터 분류
- 회귀의 경우 해당 terminal node의 종속변수값의 평균을 예측값으로 반환하지만 그 종류는 terminal node의 갯수와 일치 - 각각의 terminal node의 데이터는 '분할'되어있고, 해당 노드의 대표값( 분류 = 최빈값, 회귀 = 평균 )을 반환
- 순도(homogeneity)의 증가, 불순도(impurity)의 감소하는 방향으로 영역을 나눔 (이러한 과정을 '정보흭득' 이라 함)
- 대표적인 지표로 엔트로피가 있다.
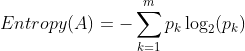
m개의 데이터가 속하는 영역 A에 대한 엔트로피를 정의하는 식
(Pk는 A영역 속에서 k범주에 속하는 데이터 비율)
위 식을 기준으로 데이터를 나누며 데이터 각각의 종류별로 가장 정보획득이 가장 큰 방향으로 나아가며 데이터 영역 분리
- 가지치기를 하여 과적합을 방지한다.
모든 termonal node의 순도가 1인 상태 (entropy =0)를 full tree라 하는데 이 상태는 입력된 data에 과적합된 상태이다. 따라서 적당한 선에서 tree의 분기를 제한하여 과적합을 방지한다.
참고 블로그 -> ratsgo.github.io/machine%20learning/2017/03/26/tree/ (출처)
1-2) Random Forest
- decision tree에서 수직적으로 데이터를 분리하는 방식이 특정한 데이터에만 유용하다는 단점이 있는데 그것을 보완한 모델
- 다수의 decision tree모델의 결과를 통합하여 리턴 (앙상블-Ensenble method: 결과를 통합하거나 합치는 방식)
- Random의 뜻은 decision tree를 만들때, 쓰이는 요소(고려하는 요소)를 무작위로 선정한다는 것.
- 무작위로 만들어진 decision tree중 가장 정확한 예측을 한 tree의 요소가 통합된 tree의 한가지 요소가 된다.
참고 블로그 -> medium.com/@deepvalidation/title-3b0e263605de (출처)
1-3) SVM ( Supprot Vector Machine )
- data를 비선형 매핑을 통해 고차원 상에서 찾은 초평면( hyperplane)으로 분리한다.
2차원에서 데이터를 분리하는 것은 선이고 3차원에서 데이터를 분리하는 것은 면이다. 그 이상의 차원에서는 초평면이라고 한다. - MMH(Maximum Marginal Hyperplane,최대 마진 초평면 )을 찾아 분리하는 방법

- 훈련 데이터에 대한 학습이 완벽하게 이루어 지지 않아도( 데이터를 완벽하게 분리하지 않아도) 최대 마진을 갖는 초평면(w)을 찾는다면 새로운 데이터가 들어오더라도 에러가 발생할 가능성이 적다.
참고 블로그-> excelsior-cjh.tistory.com/66?category=918734
1-4) SGD Classifier (Stochastic Gradient Descent Classifier ,확률적 경사 하강법)
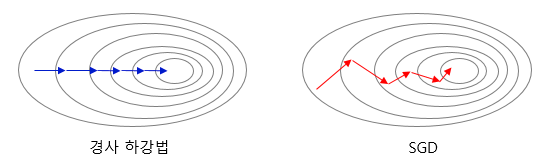
- 경사 하강법 - LOSS를 최소화하는 가중치값을 찾아가는 반복적 방법
- 일반적인 경사 하강법은 노이즈가 적가나 임의의 방식으로 최소값을 얻는데 유용하다는 장점이 있지만 '일괄 처리'로 인해 data set의 크기가 커질 경우 각 반복에 대해 참고해야 하는 데이터가 많아지므로 부담이 커진다.(시간이 오래 걸림) - 전체 데이터에서 임의로 선택된 하나의 데이터만을 참고하여(batch = 1) 경사하강법을 적용하는 방법-SGD
- 변경폭이 불안정 하고 , 일반적인 경사하강법보다 정확도가 낮은 경우가 있다.
- 일반적인 경사하강법과 비교했을 때, 속도가 빠르다.
- 하지만 노이즈가 많이 발생하고 반복이 많이 필요하다는 단점이 있다.
- 그 외 경사 하강법 -> 배치 경사 하강법, 미니 배치 경사 하강법
참고 블로그 -> wikidocs.net/36033(출처)
1-5) Logisic Regression
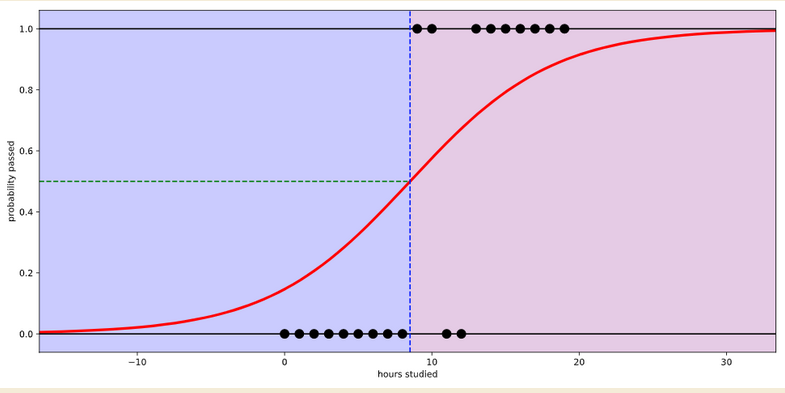
- 로지스틱 회귀 분석은 이진 분류를 수행하는 데 사용됨
- 각 속성들의 계수 log-odds를 구한 후 sigmoid함수를 적용하여 실제로 데이터가 해당 클래스에 속할 확률을 0과 1사이의 값으로 나타냄
참고 블로그 -> wikidocs.net/36033hleecaster.com/ml-logistic-regression-concept/(출처)
2. Confusion Matrix
우리가 이진 분류(True/False)를 시행할 때, True를 얼마나 정확히 예측했는가도 중요하지만 False에 대해서도 정확히 예측하였는가도 눈여겨 봐야할 부분이다.
이러한 판단을 하는데에 도움이 되는 것이 오차행렬(Confusion Matrix )이다. 즉 우리는 오차행렬을 이용하여 분류기의 성능을 결정할 수 있다. 아래 표는 spam / ham을 분류하는 이진 분류기의 오차행렬이다.
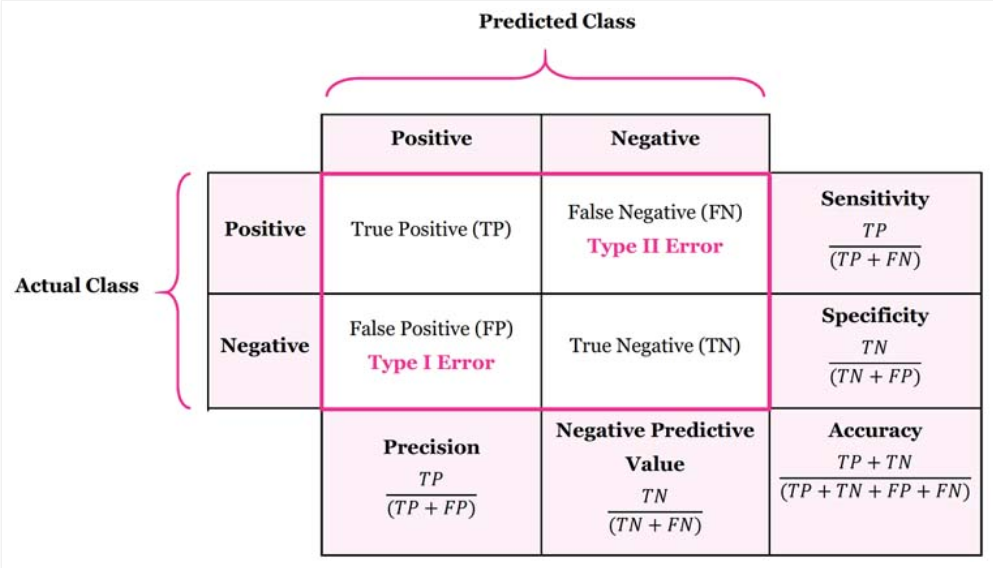
오차 행렬의 4가지 출력
- True Positive(TP)
- False Negative(FN)
- True Negative(TN)
- False Psotive(FP)
True Positive(TP) : 실제 spam에 spam 판정
False Negative(FN) : 실제 spam에 ham이라 판정
True Negative(TN) : ham에게 spam이라 판정
False Psotive(FP) : ham에게 ham이라 판정
오차핼렬을 이용한 각 출력의 수치로 계산되는 성능 지표
- 정밀도(Precision)
- 재현율(Recall,Sensitivity)
- F1 스코어(F1 score)
- 정확도(Accuracy)

각 성능지표의 계산은 위 그림과 같다. 각 지표의 계산 수식을 보았을 때,
precision : 분자 ,분모에 공통으로 존재하는 것이 TP이고 분모에 FP가 있으므로 precision 에서 중요시 하는 점은 아닌 것을 맞다고 판단하는 것을 줄여야 한다는 것이다.
Recall : precision과 비슷하게 분모에 FN이 있으므로 맞는것을 틀리다고 판단하는 것을 줄이는 것에 중점이 있다.
F1 score : precision과 recall의 조화평균으로 두 지표의 중요성이 모두 부각되는 모델에 사용하기 적합하고 지표위에 있는 1값을 바꿔줌으로써 가중평균을 적용할 수 있다.
Acurracy : 모든 경우의 수에서 정확하게 분류를 한 경우에 대해서만 고려한 지표
아래 코드를 이용하여 성능지표를 조회하는 것이 가능하다.
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
위 평가지표를 이용하여 단순히 모델의 accuracy만 높다고 좋은 모델이 아니라고 판단할 수 있어야 하며 데이터에 따라 더욱 중요시되는 성능지표를 높이기 위해 전처리 작업을 실시해햐한다.
'SSAC X AIffel > EXPLORATION_SSAC' 카테고리의 다른 글
| [EXPLORATION] 2. scikit-learn 내장 분류 모델 학습 (0) | 2021.01.23 |
|---|---|
| [EXPLORATION] 1. 간단한 이미지 분류기 구현 (0) | 2021.01.12 |

